Why Your AI Coding Agent Keeps Making a Mess
AI agents fail less because they “can’t code” and more because they lack a deterministic workflow / control flow


You’ve been here. I’ve been here. Everyone building with AI agents in 2026 has been here.
You ask the agent to add retry logic to your HTTP client. Twenty minutes later, it’s refactored your error handling, reorganized three files, added a logging framework you didn’t ask for, half-implemented a circuit breaker, and broken two tests it doesn’t know about. It cheerfully reports: “Done! I’ve improved the retry logic and made several related enhancements.”
You stare at the diff. 400 lines changed across 11 files. The retry logic is technically in there somewhere. So are five other things you now need to understand, review, test, and probably revert.
Or maybe you’ve hit the subtler version. The agent completes a task, you come back the next day, ask it to continue — and it has no idea what it did yesterday. It re-reads the codebase, makes different assumptions, and starts pulling in a different direction. Two sessions later, you’ve got contradictory changes layered on top of each other and no clear record of what was intentional.
Or the multi-agent version: two agents working on the same codebase, silently stepping on each other’s changes because neither one knows the other exists.
Here’s the thing nobody wants to admit: the agent isn’t the problem. The agent is doing exactly what a probabilistic system does when you give it freedom without structure. It’s exploring. It’s optimizing locally. It’s doing its best with the context it has.
The problem is that you’re treating it like a coworker when you should be treating it like a process.
The Uncomfortable Truth About AI Agents
There’s a fundamental tension at the heart of AI-assisted coding that most people haven’t fully internalized:
AI agents are probabilistic systems operating on deterministic codebases.
Your codebase is a precise, deterministic artifact. Every function has a defined behavior. Every test has an expected output. Every dependency has a version. The code does what it does, not what someone thinks it does.
Your AI agent, on the other hand, is a statistical machine. It produces likely outputs given its inputs. It doesn’t know your codebase — it models it, imperfectly, within a context window that it can’t carry between sessions. Every response is a roll of the dice, weighted by training but fundamentally probabilistic.
When you let a probabilistic system make unconstrained decisions about a deterministic artifact, you get entropy. Not immediately — the first few changes might look great. But over time, over sessions, over multiple agents, the chaos compounds. The codebase drifts from its intended architecture. Work becomes invisible. Changes go unverified. Nobody — human or machine — can reconstruct the chain of decisions that led to the current state.
This isn’t a model quality problem. GPT-5.3 Codex won’t fix it. Claude Opus 4.6 won’t fix it. Better coding benchmarks won’t fix it. The failure isn’t in the generation — it’s in the workflow. The agent is missing something that every functioning engineering team has: a process for turning intent into verified, trackable work.
The Five Ways Agents Fail (That Have Nothing to Do With Code Quality)
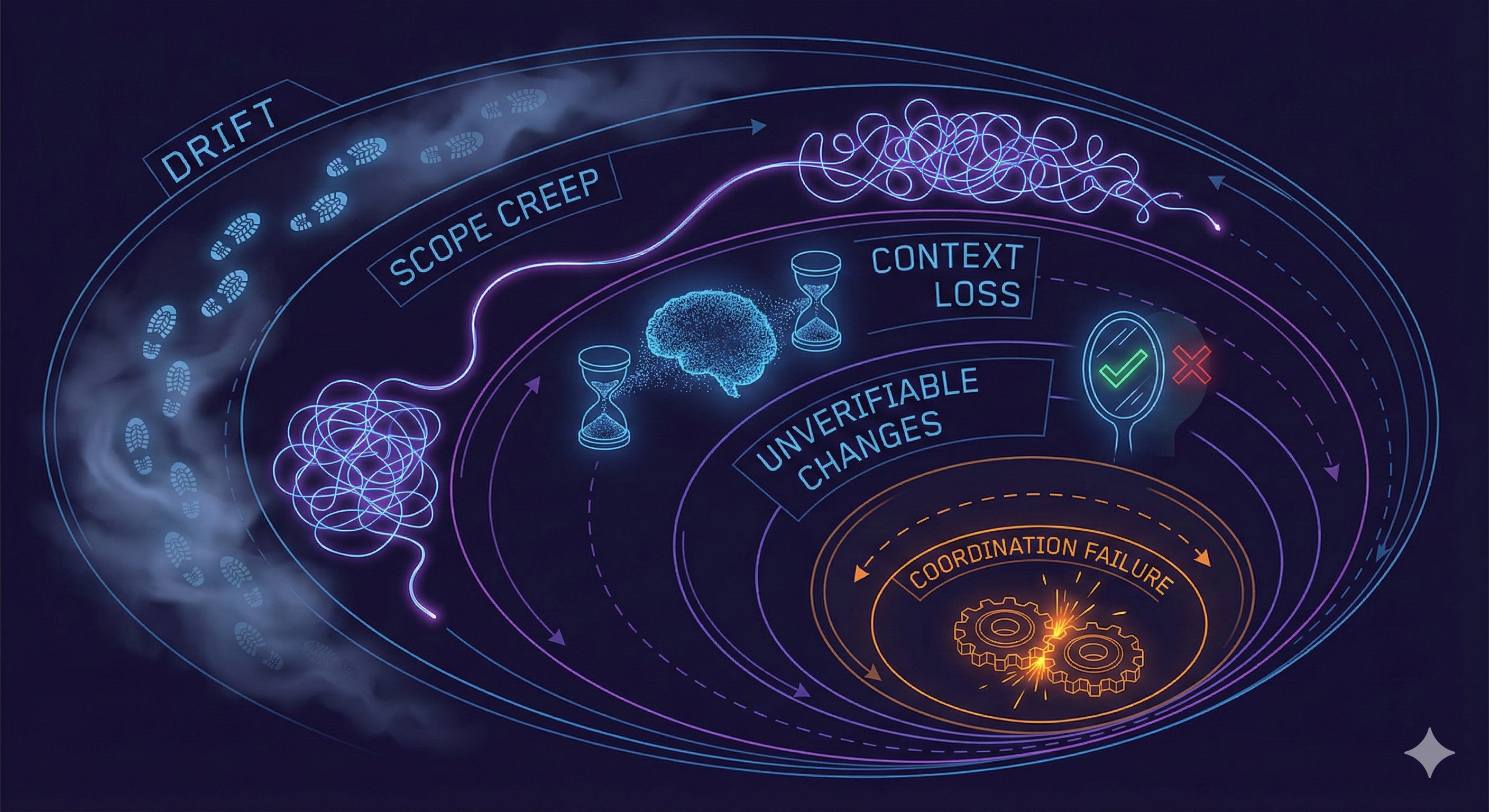
After watching agents work across dozens of projects, I’ve identified five failure modes that show up consistently. They’re not bugs in the model — they’re emergent behaviors of any system that makes probabilistic decisions without structural constraints.
1. Drift: Work Becomes Invisible
Ask an agent to work on your codebase for a few sessions. Then try to answer: what did it do? What’s left? Why did it make the choices it made?
Without a system of record, you can’t. The agent’s “memory” is its conversation history, which is session-scoped, non-portable, and usually summarized into oblivion. It completed tasks, discovered new ones, switched between them — and left no trail. The work is invisible.
This is drift. It’s the most insidious failure mode because it’s silent. You don’t notice it until you’re debugging something and realize you have no idea when or why a particular change was made.
2. Scope Creep: The Agent Chases Every Adjacent Improvement
You said “add retry logic.” But while implementing retries, the agent noticed your error handling is inconsistent. And while looking at error handling, it found a missing null check. And near that null check, there’s a function that could be more efficient. And that function uses an import that could be simplified...
Agents are incredible at finding adjacent work. They see connections humans miss. This is a feature when you’re exploring — and a catastrophic failure mode when you need a bounded, predictable change. Without constraints, “add retry logic” becomes “improve everything I can see from here.” The resulting diff is unreviewable, untestable as a unit, and nearly impossible to revert partially.
3. Context Loss: Every Session Starts From Zero
Agents are stateless between invocations. This is the hardest thing to internalize because they feel stateful — they respond to your context, they remember what you said earlier in the conversation. But that’s within-session memory. Between sessions, it’s amnesia.
A task half-done at 2 PM is a mystery at 3 PM. The next invocation either re-derives context (expensive, error-prone) or guesses (dangerous). Over multiple sessions, you get context layers — each session’s assumptions about what the previous session did, stacked on top of each other, diverging from reality.
4. Unverifiable Changes: “I Fixed It” Without Proof
Ask an agent if it fixed the bug. It will say yes. Ask it if the tests pass. It will say yes. Ask it if the feature works as specified. It will say yes.
It’s not lying — it’s predicting the most likely response to your question. Without enforcement, “done” is a claim, not a fact. The agent generated code that looks right, and its model predicts that this code probably works. But it didn’t necessarily run the tests. It didn’t verify the behavior against acceptance criteria. It didn’t check that its changes don’t break something outside its context window.
A test that asserts nothing always passes. A build that compiles an empty module always succeeds. An agent that reviews its own work will find zero issues — and that should make you suspicious, not reassured.
5. Coordination Failure: Multiple Agents Collide
This one is becoming more relevant as agent tooling improves and people start running multiple agents in parallel. Two agents working on the same codebase without explicit coordination will:
Modify the same files with conflicting assumptions
Duplicate work because neither knows the other is handling a task
Violate sequencing that matters (you can’t integrate module B before module A’s API is stable)
Create merge conflicts that neither agent understands the semantic meaning of
Without explicit sequencing, coordination is “emergent.” And emergent coordination in probabilistic systems is indistinguishable from random.
The Insight: Agents Don’t Need Better Prompts. They Need a State Machine.
Here’s where the thinking gets interesting.
Most attempts to fix agent behavior focus on better instructions. More detailed prompts. More context. Better system messages. Longer examples. And these help — up to a point. But they’re treating the symptom, not the disease.
The disease is that agents are making workflow decisions — what to work on, when to stop, how to handle discoveries, what “done” means — and these decisions are unconstrained. You’re giving them a deterministic problem (modify this codebase correctly) and letting them solve it with probabilistic judgment at every step.
The fix is to remove the probabilistic judgment from the workflow and confine it to where it belongs: the actual code generation.
Think about it this way. There are two kinds of decisions an agent makes:
What code to write — this is genuinely creative, probabilistic work. The agent’s strength.
What to work on, in what order, how to track it, when to stop, how to verify it, what to do when stuck — this is process. It should be deterministic.
Most people let the agent handle both. That’s the mistake. The code generation is the easy part. The process is where everything goes wrong.
What you need is a control flow — a state machine that dictates the agent’s workflow with the same precision that code dictates program execution. The agent follows the state machine. The state machine determines what happens next. The agent’s probabilistic creativity is channeled into a narrow, well-defined scope at each step.
This is the core idea behind a well-designed AGENTS.md: it’s not a style guide, it’s an operating system for agent behavior.
The Intent Compiler: From Fuzzy Request to Verified Change

The deepest architectural idea is that AGENTS.md should function as a compiler. Not a metaphorical compiler — a literal narrowing pipeline where each stage eliminates a class of ambiguity:
User intent
→ Outcome (what success looks like)
→ Modules (bounded subsystems)
→ Milestones (phased delivery)
→ Atomic tasks (one behavior change + one verification)
→ Dependency-ordered execution
→ Verified closeLet me walk through why each stage matters.
User intent → Outcome. When someone says “add retry logic,” what do they actually want? They want HTTP requests to survive transient failures. The outcome is: “transient 503s are retried with backoff, and the caller doesn’t see them.” This is a testable statement. The original request was not.
Outcome → Modules. What parts of the system does this touch? Just the HTTP client? The HTTP client and the configuration system (for retry parameters)? The HTTP client, config, and the health check endpoint? Drawing module boundaries prevents the agent from wandering into unrelated subsystems.
Modules → Milestones. In what order should work proceed? Design the retry interface first, then implement, then harden with edge-case tests. This phasing prevents the agent from building on a foundation that hasn’t been validated.
Milestones → Atomic tasks. Each task is one behavior change with one verification. “Add exponential backoff to HTTP client retry — verify with test_retry_backoff.” This is so precisely scoped that the agent can’t drift. There’s one thing to do and one way to prove it’s done.
Atomic tasks → Dependency-ordered execution. The tasks have an explicit order based on dependencies. Task B can’t start until Task A is done, because B depends on A’s output. This isn’t the agent’s judgment call — it’s encoded in the dependency graph.
Execution → Verified close. The task isn’t done when the code is written. It’s done when the verification command passes and the close reason includes evidence. “Added exponential backoff to HTTP client; verified with test_retry_backoff — 4/4 assertions pass.”
Each stage narrows ambiguity. By the time the agent touches code, the task is so precisely scoped that there’s almost nothing left to be probabilistic about. The creative judgment is confined to “how do I write this specific code change” — which is exactly what language models are good at.
The State Machine: Making “What Do I Do Next?” Deterministic
Here’s where AGENTS.md becomes an actual control flow specification rather than a document of good intentions.
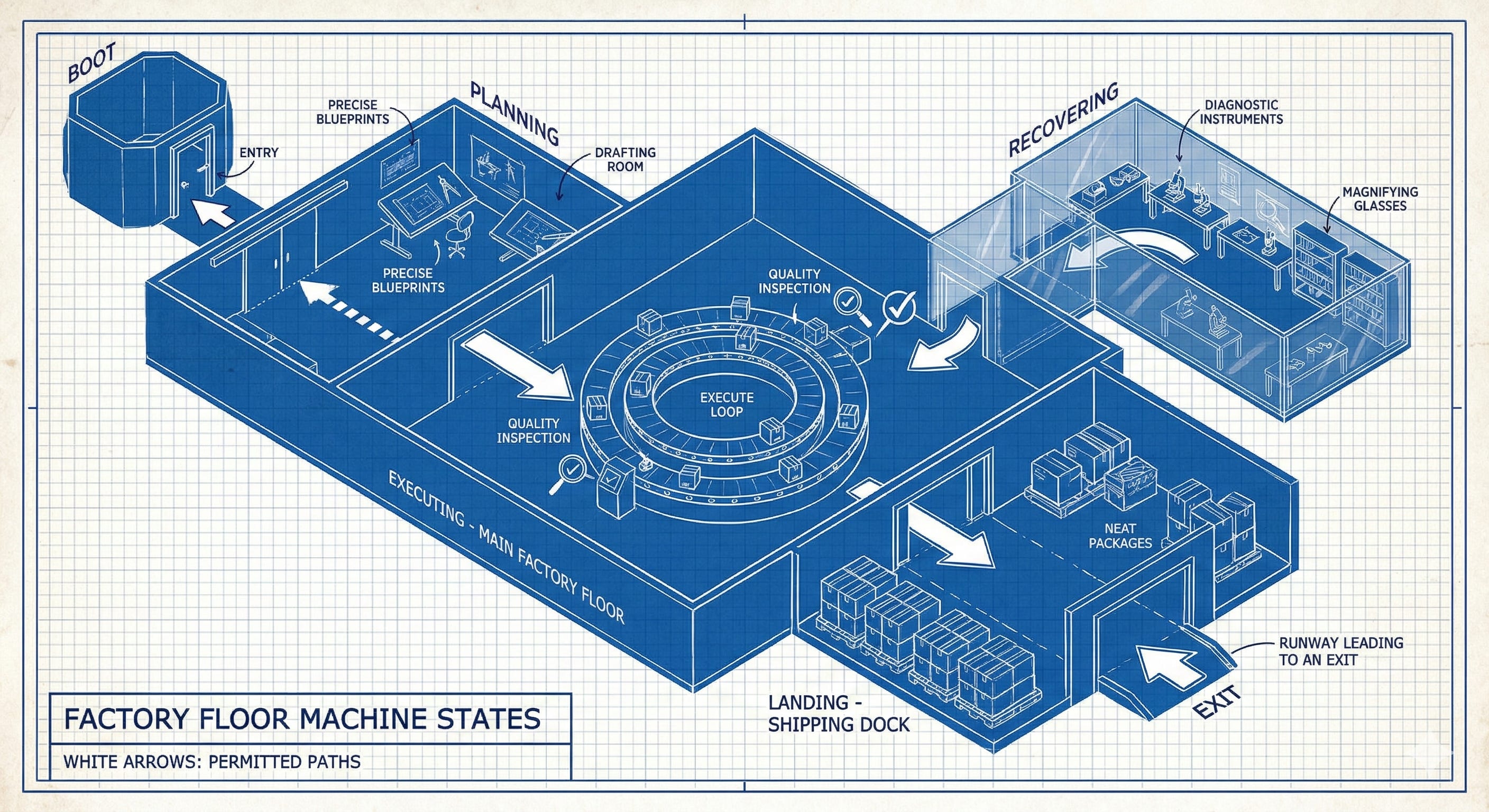
The agent operates in one of five states at any given time:
BOOT ──► PLANNING ──► EXECUTING ◄──► RECOVERING
│ │ │
│ └──────────► LANDING ──► END
│
└──── (back to PLANNING if decomposition is wrong)BOOT is session startup. The agent identifies itself, checks its configuration, and — critically — runs a resume guard: “Do I already have work in progress from a previous session?” If yes, it must deal with that first. Resume, close, block, or hand off. No new work until existing work is resolved. This single rule prevents the most common form of drift.
PLANNING is where the intent compiler runs. The agent classifies the complexity of the request and decomposes it into atomic tasks with dependencies. The key insight here is that planning depth is classified, not chosen:
Light (1–3 tasks, single module, no contract changes): Skip planning, go straight to execution.
Standard (4–7 tasks, new internal interfaces): Simplified planning — one module, create tasks, verify structure.
Deep (8+ tasks, multi-module, API/schema changes): Full decomposition with integration spines and milestone gates.
Deep is the default. You only use Light or Standard when you can prove their conditions are met. When uncertain, you plan more, not less. This is the opposite of how most people use agents (”just try it and see”), and it’s the opposite for a reason: the cost of inadequate planning is paid in drift and rework, and agents are terrible at detecting their own drift.
EXECUTING is the core loop. This is where the agent spends most of its time, and it’s where the state machine earns its keep:
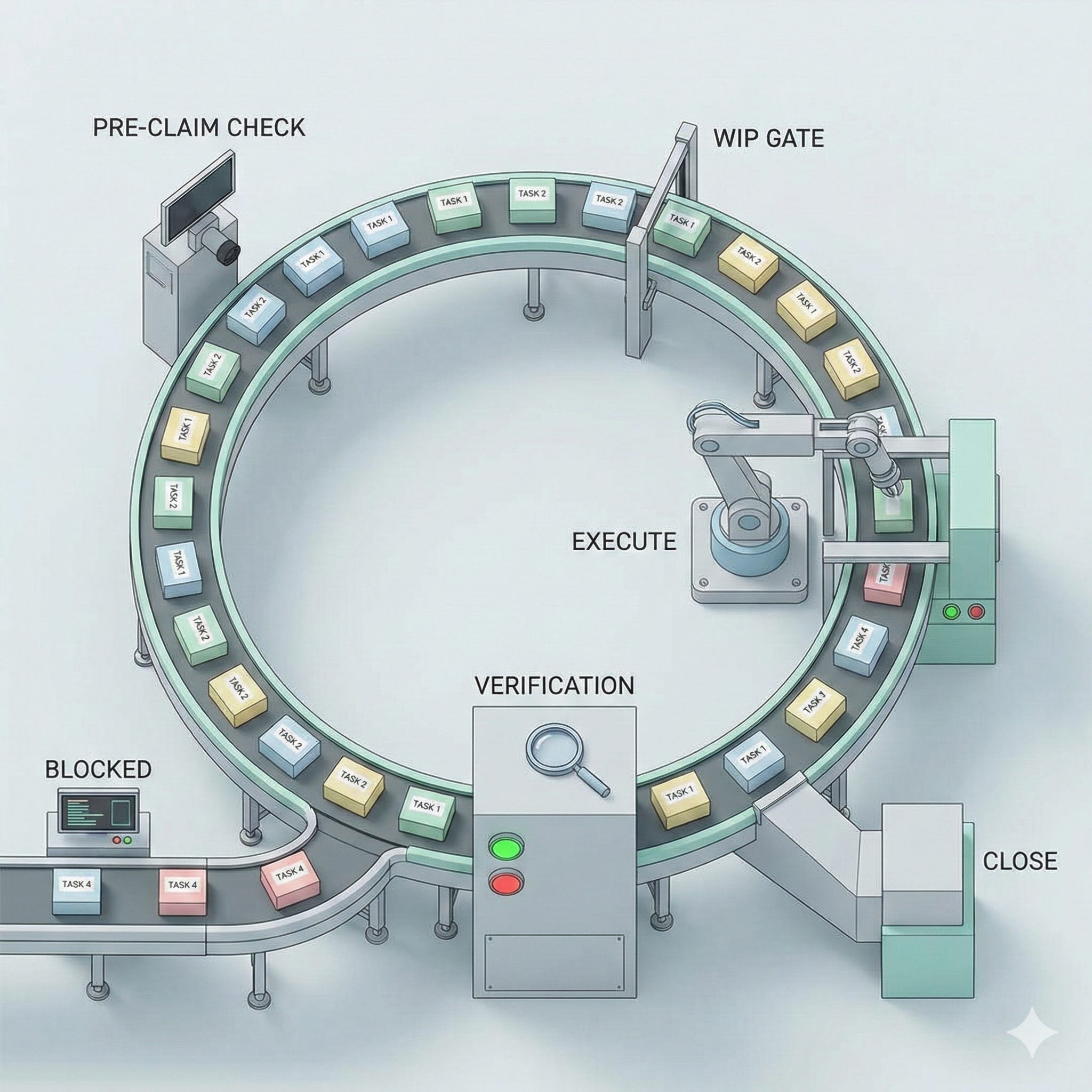
Pick work from the ready queue — not from memory, not from a TODO list, but from
bd ready, which computes transitive dependency closure and only shows tasks whose entire chain of prerequisites is satisfied.Pre-claim quality check — does this task have a description? Acceptance criteria? A verification command? If not, fix it before starting. This catches poorly-specified tasks before they produce poorly-specified code.
WIP (Work In Progress) gate — am I already working on something? If yes, I must finish, close, or explicitly hand it off before claiming new work. This is described as “the single most dangerous protocol violation” to skip, because it’s the only defense against multi-task drift, and it’s pure self-discipline.
Execute — actually write the code. This is where the agent’s probabilistic ability shines, channeled into a narrow, well-defined scope.
Discovery handling — and this is where it gets interesting. The agent will find adjacent work during execution. That’s inevitable. The question is what it does with it. The protocol defines four tiers:
Tier 1–2: Tiny correctness fixes (broken import, missing null check). ≤10 lines, same file. Fix inline, log it, move on.
Tier 3: Missing dependencies that prevent the current task. Fix if mechanical; otherwise create a blocking task.
Tier 4 (the default for any uncertainty): Structural changes, new interfaces, multi-file refactors. Create a new task. Mark it non-blocking. Continue your current work. The discovered work is quarantined — it exists in the system, it won’t be forgotten, but it won’t derail the current task.
This is the single most important mechanism for preventing scope creep. The agent’s instinct is “I found something, I should fix it.” The protocol says: “You found something. File it. Keep going.”
Pre-close checklist — before closing the task, the agent must: verify no open blockers remain, run the verification command and record output, check that the outcome matches the acceptance criteria’s intent (not just “tests pass”), verify traceability to the parent goal, and lint the close reason for unsafe keywords. Only then can it close.
Repeat.
RECOVERING activates when the execute loop stalls — when bd ready returns nothing but the project isn’t done. Without an explicit recovery protocol, agents either spin (retrying the same empty query), invent work (scope creep), or silently stop. The recover loop makes “I’m stuck” a state with defined exits:
Phase 1: Check gates, recheck scope.
Phase 2: Look for structural problems — dependency cycles, stale work-in-progress, broken dependency trees.
Phase 3: Hunt for invisible blockers — issues that look open but are actually blocked by something
bd readydoesn’t surface.Phase 4: Widen the search scope systematically.
Phase 5: Detect convergence — if the blocked-state signature hasn’t changed in three iterations, escalate to a human. Don’t loop forever.
LANDING is the shutdown sequence. Four gates, in order: clean up all in-progress work (close, block, or defer with notes), run tests/linters/build, sync and push, write a handoff artifact for the next session. No session ends without a trail. The handoff includes a next-session prompt: “Continue work on [task]. Here’s what’s done. Here’s what’s next.”
The Pieces You Need: AGENTS.md + Beads
Here’s where this gets practical. The state machine I’ve described needs two things to work:
A policy layer that defines the control flow, the transition rules, the constraints. This is
AGENTS.md.A durable state layer that persists task state, dependency graphs, claims, and status across sessions and agents. This is where Beads (
bd) comes in.
AGENTS.md supplies the constraints. Beads supplies durable task state. Together: disciplined, verifiable agent work.
What Beads Provides
Beads is a distributed, git-backed graph issue tracker designed specifically for AI agents. The things that matter for this workflow:
bd ready— a readiness oracle, not just a filter. It computes transitive dependency closure, respects defer schedules, and checks gate state. When the agent asks “what should I work on?”, this is the only answer.Dependency graph —
blocks,conditional-blocks,waits-for,parent-child. These aren’t labels — they’re the execution script. The graph determines what can run in parallel, what must be sequential, and what’s blocked.CAS claims —
bd update --claimuses compare-and-swap to prevent two agents from grabbing the same task. Distributed consensus without a central server.Git-backed persistence — issues export to JSONL, sync through git. The agent’s work survives across sessions, machines, and teams. Every state transition is a commit.
Gates — synchronization primitives. Fan-in (wait for all children), race (first success), external triggers (GitHub checks, timers). These model real workflow dependencies, not just issue hierarchy.
What AGENTS.md Provides
Everything Beads doesn’t — and can’t — enforce:
WIP=1 discipline. Beads provides CAS on individual tasks but doesn’t check global WIP count. The WIP gate is agent policy.
Planning depth selection. When to decompose thoroughly vs. when to just start coding. Beads doesn’t care — it stores whatever you create. The planning classification is policy.
Discovery quarantine. How to handle found work without derailing current work. Beads stores the new task;
AGENTS.mdsays when and how to create it and whether it blocks.Verification culture. Beads has an acceptance criteria field.
AGENTS.mdmakes running it and recording evidence mandatory.Recovery protocol. What to do when
bd readyis empty but work remains. Beads can tell you what’s blocked;AGENTS.mddefines how to unblock it.Close-reason safety. This one deserves special attention.
The Close-Reason Problem (And Why It’s Scarier Than You Think)
Beads supports conditional-blocks dependencies — fallback paths that activate when a predecessor fails. The failure detection works by scanning the close reason for keywords like “failed,” “timeout,” “error,” “blocked.”
Agents are notoriously sloppy with natural language. Without explicit rules, an agent will write a success close reason like “Fixed the error handling in retry path” — which contains the word “error” and will falsely activate fallback paths. Silently. You won’t know until downstream tasks start executing a contingency plan that shouldn’t be running.
The AGENTS.md protocol codifies rules: success reasons must start with past-tense change verbs (”Added,” “Implemented,” “Refactored”). Failure reasons must start with “failed:”. Eleven keywords are banned from success reasons. A mandatory lint runs before every close.
This is a case where policy must exist because the tool doesn’t enforce the constraint. bd close doesn’t validate close reasons. The lint in AGENTS.md is the only defense against a class of silent coordination bugs that are nearly impossible to debug after the fact.
A Session, Start to Finish
Let me walk through what this looks like in practice. Not the theory — the actual sequence of events.

Session starts. The agent runs bd prime, resolves its identity, checks config. Then: resume guard.
$ bd list --status in_progress --assignee “agent-1”Empty. No prior work. Good.
User request arrives: “Add retry logic to the HTTP client.”
Intent translation. Before writing any code, the agent translates:
Outcome: transient 503s are retried with exponential backoff; callers don’t see transient failures.
Module: HTTP client (
pkg/httpclient).Milestone: implement → harden.
Tasks: (1) Add retry with backoff to HTTP client, (2) Add configurable retry parameters, (3) Add edge-case tests for retry exhaustion.
Complexity classification: 3 tasks, single module, no API change → Light. Skip full planning, enter execute loop.
The agent creates three tasks in Beads with descriptions, acceptance criteria, and verification commands. Task 2 depends on Task 1. Task 3 depends on Task 2.
Execute loop begins.
$ bd ready --label module/httpclient
→ Task 1: “Add retry with exponential backoff to HTTP client”Pre-claim check: description ✓, acceptance ✓, verification command (go test ./pkg/httpclient/... -run TestRetryBackoff) ✓.
WIP gate: no in-progress issues ✓.
Claim: bd update TASK-1 --claim.
The agent writes code. This is where its probabilistic ability shines — channeled into a narrow scope. It adds a retry wrapper with exponential backoff to the HTTP client.
Discovery. While implementing, the agent notices the HTTP client doesn’t close response bodies in error paths. A resource leak. Its instinct says: fix it.
The protocol says: classify. This is a correctness bug in the same file (Tier 1–2, ≤10 lines). Fix it inline, log it:
$ bd update TASK-1 --append-notes “Inline fix (T1): added defer resp.Body.Close() in error path”Continue with the retry logic. Don’t create a new task. Don’t switch context.
Then the agent notices the connection pool configuration is suboptimal. This could affect retry behavior under load. Its instinct says: fix it.
The protocol says: classify. This is a structural change to connection management, touches configuration, might affect other callers (Tier 4). Create a task, quarantine it:
$ bd create “Optimize HTTP client connection pool settings” -t task \
--parent $MILESTONE --labels module/httpclient \
--description “Connection pool defaults may cause retry storms under load...” \
--acceptance “Connection pool configured with per-host limits...”Non-blocking by default. The agent continues working on Task 1.

Pre-close. Retry logic is implemented. The agent runs the pre-close checklist:
Blocker check:
bd dep tree TASK-1 --direction up— no open blockers ✓Verification:
go test ./pkg/httpclient/... -run TestRetryBackoff→ 4/4 pass ✓Goal-backward check: retry.go exists, contains actual backoff logic (not stubs), test assertions check actual retry counts ✓
Traceability: close reason maps to acceptance (”retry with exponential backoff”) maps to outcome (”transient failures handled”) ✓
Close-reason lint: “Added exponential backoff retry to HTTP client” — no failure keywords ✓
$ bd close TASK-1 --reason “Added exponential backoff retry to HTTP client; verified with go test ./pkg/httpclient/... -run TestRetryBackoff — 4/4 pass”Loop repeats. bd ready now shows Task 2 (unblocked because Task 1 closed). Claim, execute, verify, close. Then Task 3.
Ready queue empty. All three tasks closed. The discovered connection pool task is in the backlog but wasn’t blocking. The agent enters the landing sequence.
Landing. Gate 1 (issue hygiene): no in-progress work ✓. Gate 2 (code quality): tests pass, no lint violations ✓. Gate 3 (sync): bd sync, git push ✓. Gate 4 (handoff):
Next session prompt: “Retry logic complete for HTTP client (TASK-1, TASK-2, TASK-3 closed).
Discovered: TASK-4 (connection pool optimization) is open and unblocked.
Next: bd ready to pick up remaining work.”Session ends cleanly. The next session — whether it’s the same agent, a different agent, or a human — can pick up exactly where this left off.
The Deeper Point: Constraints Are What Make Agents Useful
There’s a counterintuitive truth here that goes against the grain of how most people think about AI: more constraints produce better outcomes.
The natural instinct is to give agents maximum freedom. “You’re smart, figure it out.” And for simple, single-shot tasks, that works fine. But for sustained work on real codebases — the kind that spans sessions, touches multiple modules, requires coordination — freedom is the enemy.

Every unconstrained decision point is an opportunity for probabilistic drift. The agent might handle it well. It might not. Over enough decisions, “might” becomes “won’t.” The entropy compounds.
The AGENTS.md state machine removes discretion from workflow decisions and concentrates the agent’s probabilistic power where it belongs: generating code within a tightly scoped task. The agent doesn’t decide what to work on (the dependency graph decides). It doesn’t decide when it’s done (the verification command decides). It doesn’t decide how to handle discoveries (the tier classification decides). It doesn’t decide what to do when stuck (the recover loop decides).
What’s left is the thing language models are genuinely extraordinary at: understanding code, reasoning about behavior, and writing changes that accomplish a specific, well-defined goal.
An agent that can do anything will do everything. An agent that follows a state machine will do exactly what’s needed, prove it worked, and leave a trail for the next session.
That’s not a limitation. That’s the whole point.

Getting Started
The reference AGENTS.md specification is available here. It includes the complete state machine, all nine transition rules, the five-phase recover loop, the decomposition algorithm, close-reason convention, and troubleshooting guide.
If you’re ready to try this:
Install Beads and initialize it in your repo.
Drop the reference
AGENTS.mdin your repo root.
The first time you watch an agent hit the WIP gate and stop itself from chasing a tangent — file a task instead, continue its current work, close with verification evidence, and hand off cleanly — you’ll understand why the constraints matter.
Your agent was never bad at coding. It was bad at working. Now it has a process.
Beads is a distributed, git-backed graph issue tracker built for AI agents. The reference AGENTS.md is here.